Initial Exploration
07 Jul 2015Empezamos analizando la tabla basic_stats, que contiene la siguiente información:
merchants Number of merchants
cards Number of differents cards
payments Number of transactions
avg payment Average transaction
max payment Maximum transaction
min payment Minimum transaction
std Standard deviation
| zipcode | date | category | merchant | card | payment | avg | max | min | std | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 8001 | 2014-07-01 | es_barsandrestaurants | 76 | 405 | 410 | 27.28 | 600 | 0.1 | 47.25 |
el importe de total de transacciones:
214 Millones de Eur.
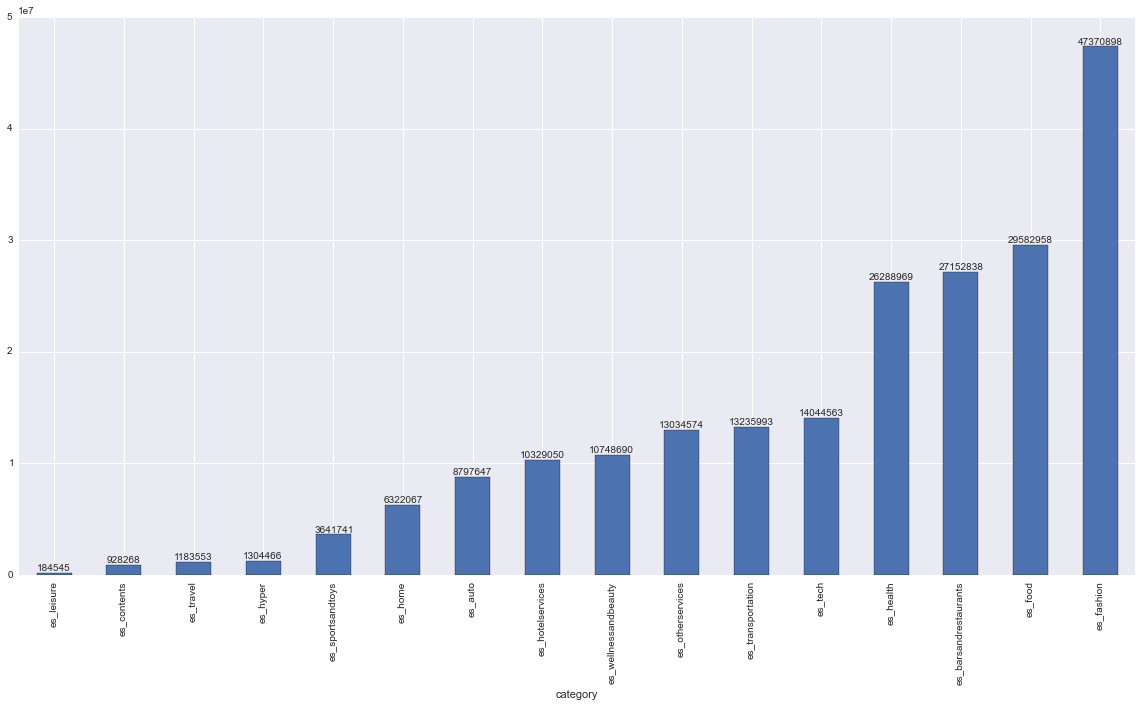
y su distribución por categorías:
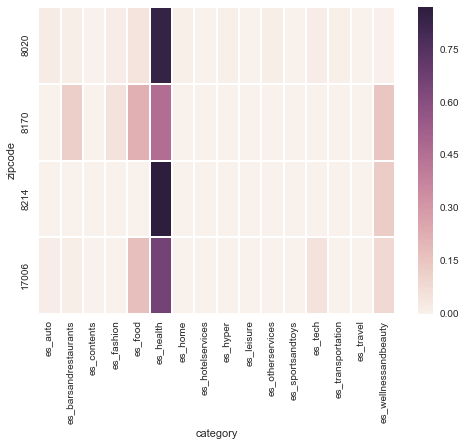
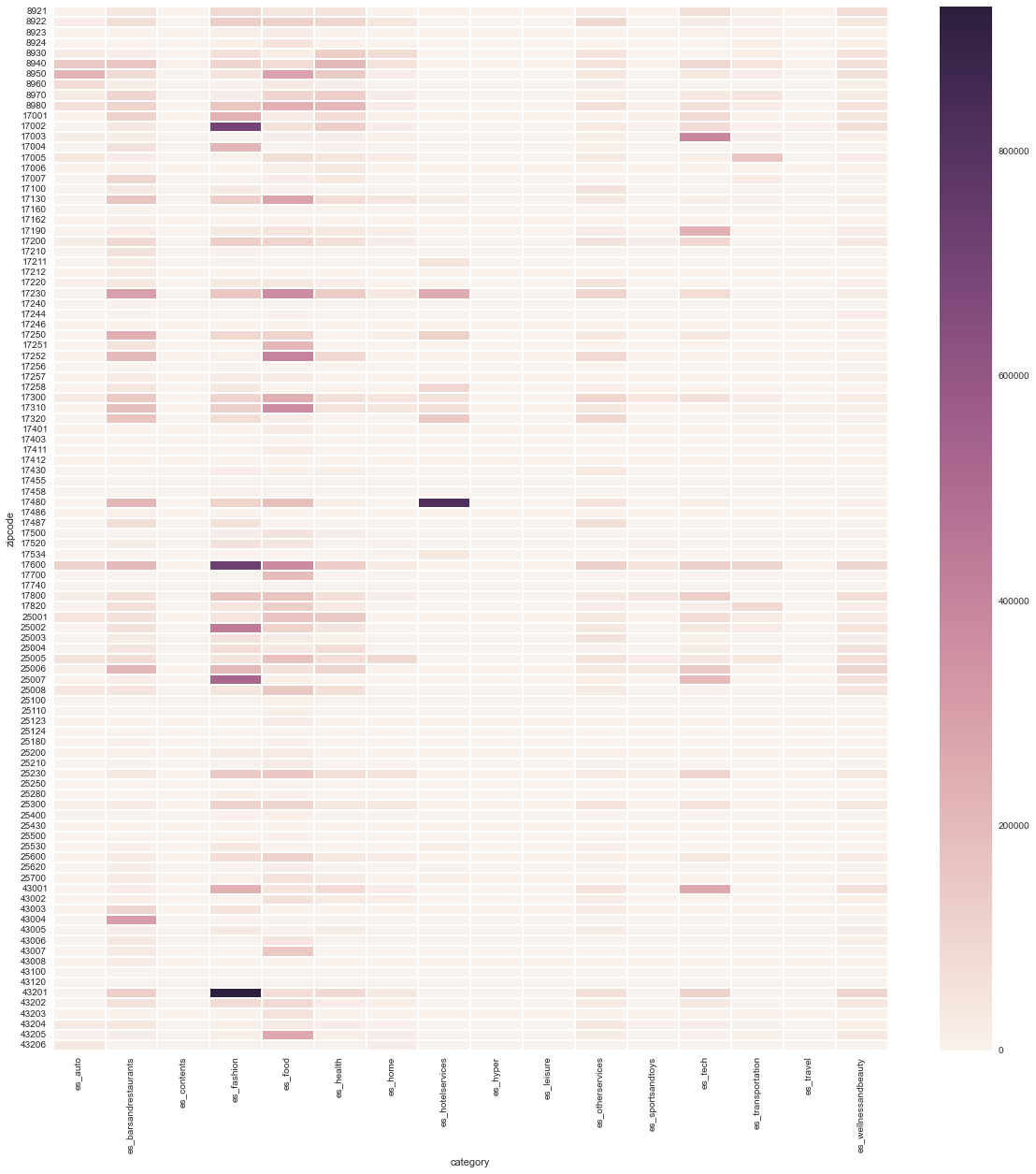
un subset de su distribución por zipcodes:
estamos en el mes de Rebajas!
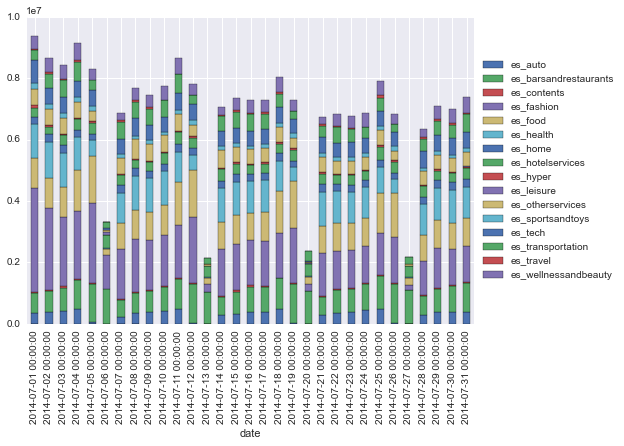
evolución de lo gastado por categorías por date:
evolución del gasto en Bars&Restaurants:
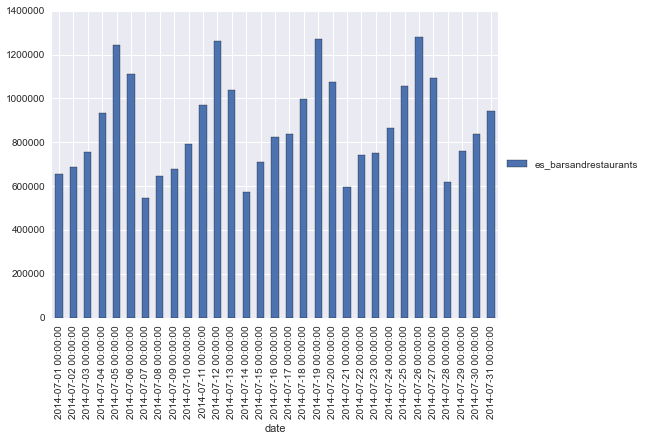
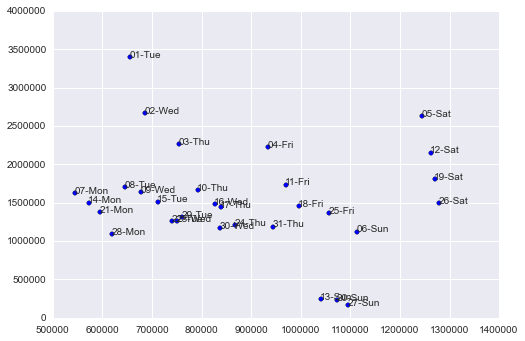
relación del gasto en Bars&Restaurants y el gasto en Fashion en función del día de la semana:
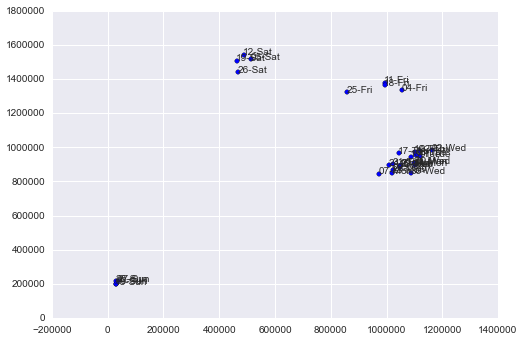
relación del gasto en Health y el gasto en food en función del día de la semana:
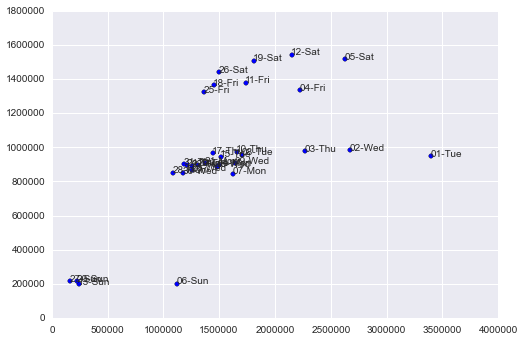
relación del gasto en fashion y el gasto en food en función del día de la semana:
relación del gasto en Bars&Restaurants, fashion y en food en función del zipcode:
headmap global, ordenando por gasto en fashion, y food:
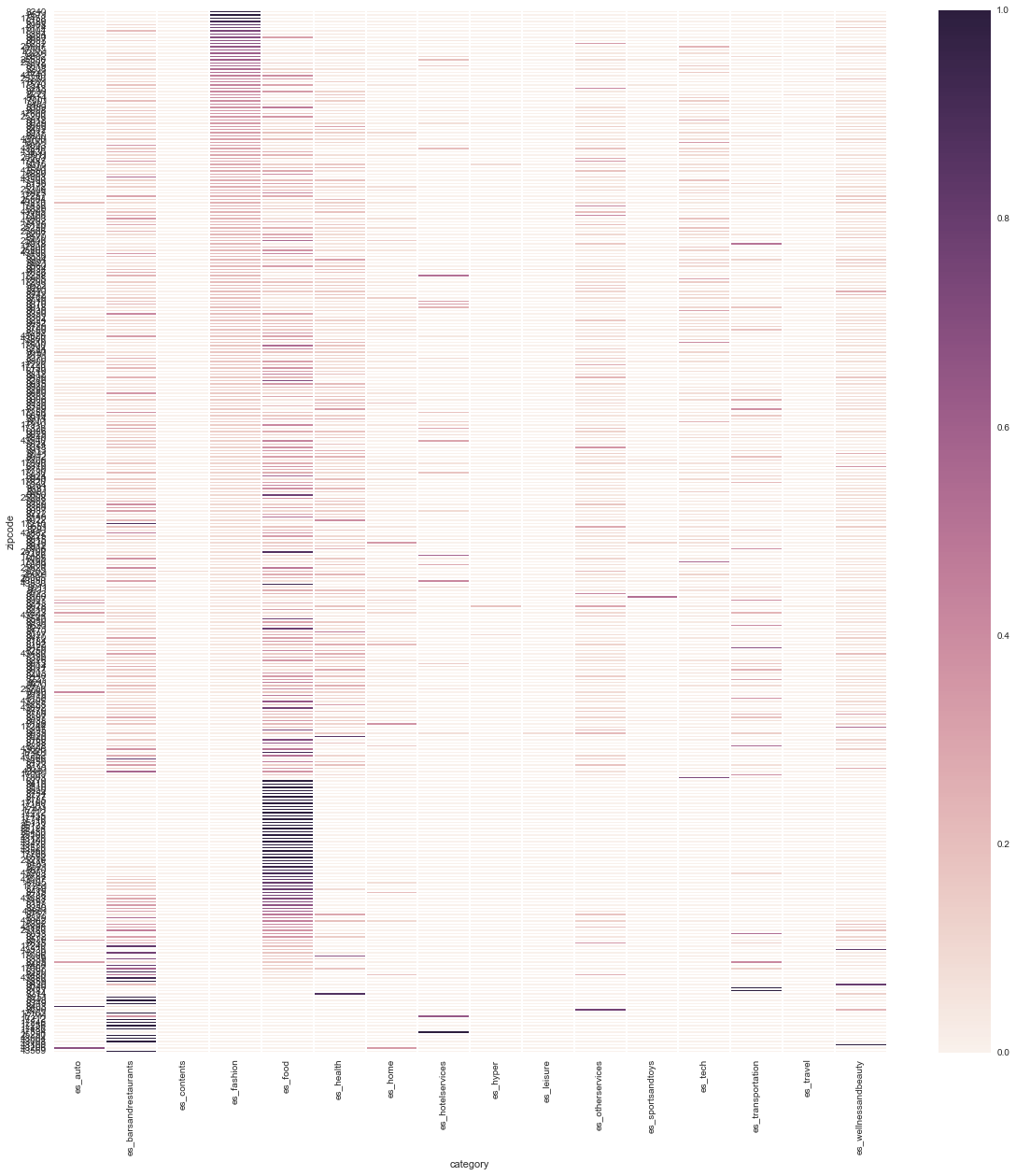
después de este Analysis inicial, vemos que hay zipcodes como Vic, Figueres que tienen una distribución más uniforme de gasto en casi todas las categorías, zipcodes con todos los servicios, mientras que otros tienen una concentración alta de un determinado servicio.
utilizamos KMeans para ver diferentes clusters de zipcodes, K=3, K=10, K=20,
from sklearn import cluster
K=20 # Assuming to be 3 clusters!
clf = cluster.KMeans(init='random', n_clusters=K, random_state=0)
clf.fit(zipbycategory_row_norm)
print clf.labels_
sns.heatmap(zipbycategory_row_norm[clf.predict(zipbycategory_row_norm)==0])
[ 2 8 11 5 5 5 8 11 5 16 5 11 5 11 5 11 5 11 8 0 11 5 18 5 1
1 17 18 11 2 1 1 14 5 5 5 5 17 14 1 17 4 12 17 5 15 17 14 12 0
11 5 6 6 17 17 3 1 14 1 1 12 1 1 17 17 14 1 1 8 17 17 18 0 11
17 9 1 17 17 17 14 12 8 6 8 11 9 17 10 12 3 12 19 1 1 17 12 11 11
17 8 17 17 12 19 1 13 1 10 10 19 18 19 5 5 15 10 19 5 11 11 9 3 12
14 7 17 19 13 19 13 18 17 3 9 3 11 12 3 18 3 17 15 6 11 14 17 18 1
12 3 8 18 1 1 13 17 1 3 5 17 12 14 11 1 3 1 3 17 3 12 12 15 11
2 17 11 1 5 1 10 5 16 15 1 5 11 1 2 14 14 6 11 1 17 17 17 11 14
11 1 15 17 1 5 17 9 5 1 11 8 2 8 14 0 13 18 17 3 10 2 11 10 16
10 18 5 13 7 10 5 12 19 10 19 16 1 17 16 3 3 3 3 18 3 6 16 10 18
17 15 16 11 3 3 11 17 17 8 18 11 1 11 8 17 3 3 3 3 19 15 3 1 10
15 11 15 3 3 8 15 19 17 2 17 13 10 11 19 12 10 7 3 8 11 3 5 12 9
3 7 19 3 5 19 11 3 3 17 3 10 15 11 15 1 19 11 11 16 13 11 10 12 19
12 19 12]
ejemplo del cluster "Zipcodes Health" con K=20